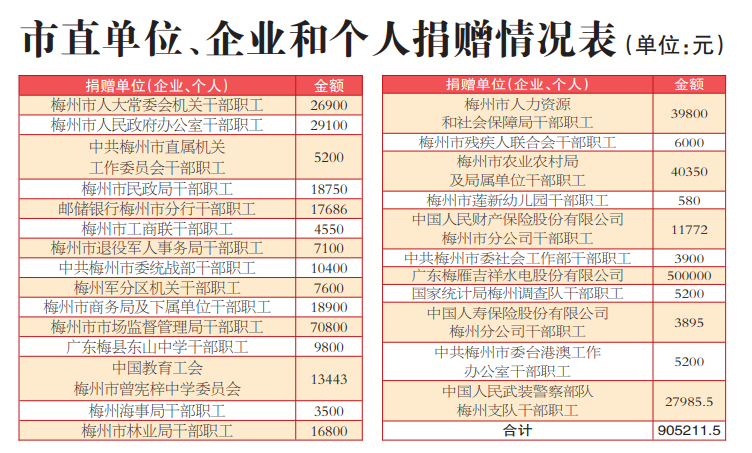
山东省市场监管局多措并举为北京2022年冬奥会和冬残奥会顺利举办保驾护航 知识 2025-12-18 22:10:38 <<梅州65家企业榜上有名!2025创新型中小企业和通过复核的创新型中小企业名单公布 “秋冻”“贴秋膘”有讲究!专家回应秋季养生热门话题>> 最新资讯 农业总产值增速创三年新高!广州市番禺区“百千万工程”初见成效 福建开展个人消费贷款纾困专项行动 24小时、34分钟、30秒 三组数据看合福高铁新跨越 收到爱心捐款90.52万元!社会各界积极参与“6·30”活动